Passing Bablok is biased at low data precision (thus almost always)
Recently I realized that in the new version of the R {mcr} package the “equivariant Passing Bablok” regression is available Jakob Raymaekers, F. Dufey, arxiv, 2022 with the option “method.reg=PBequi” for the function mcreg() .
This version of PaBa is a big step forward in that it can be used even in the case where the null hypothesis does not strictly involve an intercept of zero and a slope of one. In fact, any use of the traditional 1983 PaBa method outside of this condition is generally not correct.
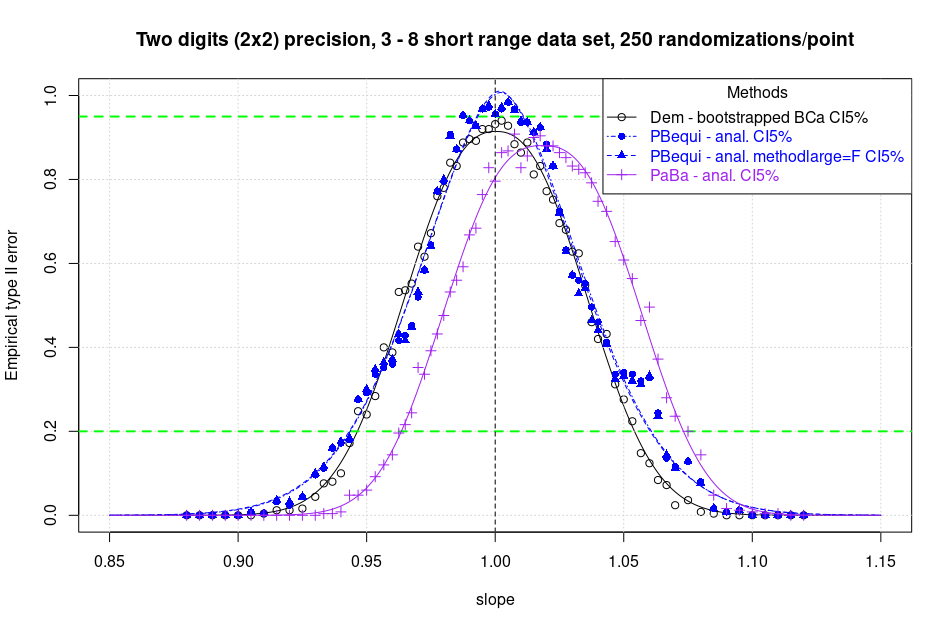
Attention has fallen on checking the presence of a bias when the data have low precision and thus ties (or ties in the pairwise slopes) are present. Notoriously, the classical method suffers from a very strong bias G. Pioda, 2021, pag. 31 and should never be used unless the precision of the data is at least 4 significant digits.
A first limited simulation with the same method published in 2021 (but with a resolution of 250 replications instead of 400) shows that indeed PBequi is definitely a big step forward in this as well. The coarse bias is dramatically reduced. But unfortunately it is not clearly eliminated. Note in this regard the asymmetry of the power curves at the 80 percent level (validation not rejected at 20 percent) in green in the graph provided here. Further investigation is needed to completely exclude the bias or to asses its magnitude.
Take home message. I suggest to all those who intend to use the PaBa method to abandon the classical 1983 algorithm in favour of the equivariant version offered by the R {mcr} package.
Remark: Unfortunately in these first runs at low data precision some unclear stability problems of the PBequi function in R prevented a simulation of the bootstrapped CI methods. It’s not clear if this issue is a local computational limit arising from the limited IT resources or something else.